生成式做信息检索
本文介绍用单个 Transformer 利用Seq2Seq的结构完成信息检索,所有关于语料库的信息都被编码在模型的参数中。 本文还引入可微搜索索引 (DSI-Differentiable Search Index),学习text- text模型的新范式,将字符串查询直接映射到相关文档; 换句话说,DSI 模型直接回答查询,仅使用其参数,大大简化整个检索过程。 这里其实比较重要的是文档及id的定义和表示,以及模型和语料库大小之间的相互作用。 实验表明,给定适当的设计选择,DSI 明显优于强基线,例如双编码器模型(Dual Encoder)。 此外,DSI展示了强大的泛化能力,在零样本设置中优于 BM25 基线
模型适用性
个人感觉适用小的召回doc集场景,比如百万以内
优势
简单;没有DE的双编码过程,没有向量检索过程;检索效率高
和普通的双塔模型比较
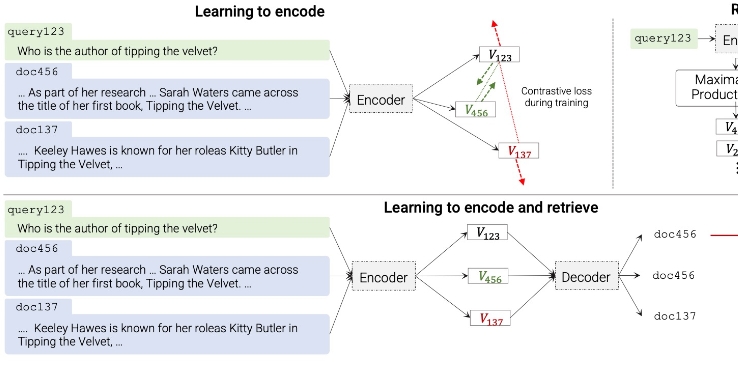
双塔模型:query 和doc 分别encoder,然后做内积得到score,然后开始rank
DSI:seq2seq的框架,query进行encoder,然后再decoder阶段,直接生成docid,然后利用beam search的方式生成字符串,表示docid
模型
如何将doc表示成序列的方式
如果将doc表示成序列的方式,比如字符串序列docids,这样有利于decoder阶段进行生成;然后通过表示序列召回doc。所以怎么生成docids,且和doc能做映射,这个是关键的技术点
索引样本怎么构造:
直接定义:doc的前N个token代表docid – 最佳
重复出现的词&词组
doc分块,随机对用几个分块来表示doc
不同的索引对应的检索方法
如何快速的decode 出docid,取决于docid的表示;所以怎么构建docid非常重要
非结构化原子标识符:Unstructured Atomic Identifiers
相对就是一个N(Doc数)分类的问题了
原始字符串表示:Naively Structured String Identifiers
docid表示成一个字符串,decode阶段依次解码,这个方法就避免直接学习docid的表示,但不是直接生成K个doc,生成的是字符串;但好处是搜索构建beam search tree 可以构建 top-k的空间,这样非常高效
语义结构表示:Semantically Structured Identifiers
语义结构灌输给 docid 空间可以带来更好的索引和检索能力
目标是自动建立这种标识:1) docid 应该捕获一些关于其相关文档语义的信息;2)docid 的结构应该在每个解码步骤之后有效地减少搜索空间,这带来的结果是语义相似的文档共享的标识前缀是相似的
在文档embedding上使用简单的层次聚类过程来诱导十进制树
给定一个要索引的语料库,所有文档都聚集成 10 个簇。每个文档都分配有0-9的一个标识符。
对于包含超过 c 个文档的每个集群,递归应用该算法,将下一级的结果附加到现有标识符后面。
如:利用k-mean对bert的encoder结果进行聚类,c=100
这样生成的doc表示就是一个序列标识符
训练
两种训练方法:



